
Franz Kafka y el mundo digital contemporáneo pueden parecer universos dispares a primera vista, pero al examinar más de cerca La Metamorfosis de Kafka y la evolución del fraude de identidad, encontramos similitudes en la transformación y despersonalización de la identidad.
En La Metamorfosis, Gregor Samsa se despierta un día convertido en un insecto, un cambio radical que altera la percepción de sí mismo y de cómo lo ven los demás. De manera análoga, la evolución del fraude de identidad implica una metamorfosis en la forma en que los individuos son vistos y percibidos en el mundo virtual. La identidad digital puede ser manipulada y distorsionada, llevando a una pérdida de control sobre la propia imagen como es en el caso de los deepfakes.
En la obra de Kafka, la nueva forma de Gregor provoca una ambigüedad en su identidad y propósito en el mundo. En el ámbito digital, la identidad se vuelve igualmente ambigua, ya que los ciberdelincuentes que llevan a cabo este tipo de fraudes pueden crear perfiles falsos o utilizar información robada para difuminar las líneas entre lo auténtico y lo falso.
Tanto en La Metamorfosis como en el fraude de identidad digital, los protagonistas enfrentan una realidad desconcertante y a menudo incomprensible. Gregor lucha por adaptarse a su nueva forma, mientras que las víctimas de este tipo de fraude a menudo se enfrentan a la dificultad de comprender cómo ocurrió la suplantación y qué medidas deben tomar para restaurar su identidad.
Sin embargo, esta amenaza no solo atenta contra el estado civil de las víctimas sino también contra las empresas que ven franqueados sus procesos y sistemas.
Este artículo se sumerge en el arte de abordar los nuevos desafíos de fraude de identidad, proporcionando no solo una visión clara de la problemática, sino también posibles soluciones e investigaciones para detectar el fraude y para proteger la integridad y seguridad de los usuarios. Desde los conjuntos de datos para conseguir un sistema robusto de detección de deepfakes, pasando por enfoques recientes hasta llegar a las medidas de autenticación avanzada.
Pero antes detengámonos en analizar la evolución de este tipo de fraude.
La evolución del fraude de identidad
En los inicios, el fraude de identidad se basaba en la mera usurpación de documentos físicos, como pasaportes y DNI. Los estafadores utilizaban técnicas como el robo de carteras o la manipulación de documentos para obtener información personal de sus víctimas. Una vez en posesión de estos documentos, podían realizar transacciones fraudulentas o incluso cometer delitos en nombre de la persona afectada.
Con el avance de la tecnología, el fraude de identidad evolucionó para aprovechar las vulnerabilidades en los sistemas informáticos y las redes de comunicación. Esto dio lugar a lo que ahora conocemos como «ciberfraude de identidad«. Los delincuentes comenzaron a utilizar ingeniería social para robar datos de bases de datos para obtener información confidencial, como contraseñas, números de tarjeta de crédito y números de seguridad social. Además, el surgimiento de técnicas como los ataques de presentación (spoofing) y el uso de deepfakes añaden capas adicionales de complejidad al fraude de identidad, permitiendo a los estafadores manipular información y crear contenido falso de manera más convincente.

La proliferación de las redes sociales y la información disponible online ha proporcionado a los estafadores una fuente adicional de datos personales. Pueden recopilar información sobre las actividades, intereses y relaciones de las personas a través de perfiles en redes sociales, lo que les permite crear perfiles falsos de manera más convincente.
Otra evolución importante es el aumento del robo de identidad para cometer fraudes financieros. Los delincuentes pueden abrir cuentas bancarias o solicitar préstamos utilizando la información personal de la víctima, lo que puede tener graves consecuencias financieras y legales para la persona afectada.
Nuevas oportunidades para el fraude de identidad digital
El avance de la tecnología también ha abierto nuevas oportunidades para el fraude de identidad digital. La adopción generalizada de tecnologías biométricas, como el reconocimiento facial, ha llevado a un aumento en los intentos de suplantación utilizando métodos de ingeniería inversa. Los estafadores buscan formas de burlar estos sistemas de seguridad de alta tecnología, lo que plantea un desafío adicional para la protección de la identidad digital.
Además, el fraude de identidad sintética, que combina elementos de información real y falsa para crear una identidad completamente ficticia, representa una amenaza creciente. Asimismo, el SIM swapping, donde los atacantes persuaden a los proveedores de telefonía móvil para que transfieran el número de teléfono de la víctima a una tarjeta SIM controlada por el atacante, proporciona acceso a mensajes de texto y llamadas, eludiendo la autenticación de dos factores y accediendo a cuentas digitales.
Detección de deepfakes
Con la irrupción de diversas arquitecturas de aprendizaje profundo se han logrado avances notables en el campo de la falsificación de imágenes y vídeos. Esto ha resultado en un aumento sorprendente en la producción de contenido multimedia falso, impulsado por una mayor accesibilidad y requisitos de capacitación más bajos. No solo ha crecido la cantidad de este tipo de contenido, sino que también su nivel de sofisticación ha mejorado enormemente, llegando a ser a veces indistinguible de los vídeos reales.
Un ejemplo de ello ocurrió en las elecciones de Delhi en 2020, cuando se creó un vídeo deepfake de una figura política popular, el cual se estima que fue visto por alrededor de 15 millones de personas. Ante el abuso y el potencial impacto de los deepfakes, es imprescindible contar con métodos de detección más efectivos y robustos.
Conjunto de datos para detectar deepfakes
El diseño de un sistema confiable de detección de deepfakes requiere el acceso a conjuntos de datos extensos de deepfakes para su entrenamiento.
La Tabla 1 recoge las características principales de los conjuntos de datos de deepfake disponibles públicamente. La mayoría de estos conjuntos contienen imágenes de alta resolución con un solo rostro en la imagen, aunque algunos incluyen deepfakes generados con técnicas de generación múltiple y múltiples niveles de compresión. Actualmente la mayoría de los contenidos se comparten a través de la web y redes sociales por lo que es común que los vídeos e imágenes se compartan en baja resolución para una transmisión más eficiente. Asistimos cada vez más a casos de vídeos falsos en entornos sin restricciones, como oclusiones en el rostro (como lentes, sombreros, gorras, turbantes o hiyabs) y múltiples rostros con variaciones de pose.
Tabla 1. Comparación cuantitativa de DF-Platter con los conjuntos de datos Deepfake existentes
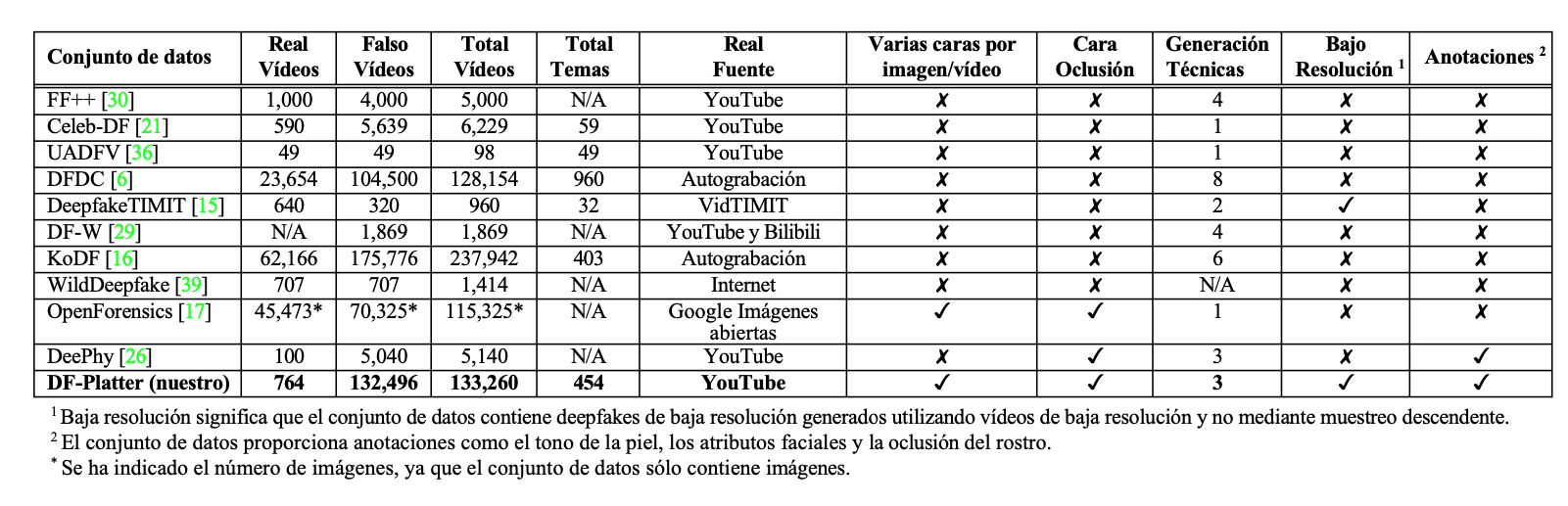
Nota. Narayan, Agarwal, Thakral, Surbhi, Vatsa, and Singh (2023, p. 2)
Hasta ahora, los conjuntos de datos existentes han consistido principalmente en deepfakes de un solo sujeto generados mediante una sola técnica. Sin embargo, también es factible crear deepfakes con múltiples sujetos falsificados. Recientemente, los desarrolladores de Collider lanzaron un deepfake con múltiples rostros falsos en un solo fotograma. El vídeo, titulado «Deepfake Roundtable«, presenta una discusión entre deepfakes de cinco personalidades famosas.
DF-Platter y KoDF
Los conjuntos de datos como DF-Platter y KoDF juegan un papel crucial en la detección de deepfakes, configurándose como herramientas esenciales para entrenar y evaluar algoritmos de detección de deepfakes, proporcionando una variedad de ejemplos que representan diferentes técnicas de falsificación y escenarios, permitiendo a los modelos de detección aprender a reconocer deepfakes en una amplia gama de situaciones.
Asimismo, estos conjuntos de datos pueden abarcar deepfakes con oclusiones (como gafas, sombreros, etc.) y otros desafíos que complican la detección. Esto es esencial para entrenar modelos que puedan reconocer deepfakes incluso en condiciones adversas. Además, a menudo están acompañados de anotaciones que proporcionan información sobre las técnicas de falsificación utilizadas, la calidad de la falsificación y, en algunos casos, información contextual adicional.
Por último, permiten evaluar el rendimiento de los algoritmos de detección en condiciones realistas y diversas, lo cual es esencial para garantizar que los modelos sean robustos y efectivos en situaciones del mundo real.
Sin embargo, como las falsificaciones son cada vez más realistas se hace cada vez más difícil detectar rastros de falsificación sutiles y locales.
Nuevos enfoques para la detección de ataques de presentación
A medida que las tecnologías de suplantación de identidad se vuelven más sofisticadas, la detección demanda constantemente nuevos enfoques. Los siguientes enfoques se basan en como hacer que la inteligencia artificial sea capaz de generalizar y adaptarse para detectar nuevos ataques. Es importante indicar que se trata de investigaciones y que posiblemente marquen el futuro a una detección más avanzada del fraude de identidad.
Enfoque FLIP: suplantación de caras entre dominios con orientación lingüística
FLIP es un enfoque novedoso para la detección de ataques de presentación (FAS) en sistemas de reconocimiento facial, que utiliza el pre-entrenamiento de lenguaje-imagen contrastiva (CLIP) para mejorar la generalización en la detección anti-spoofing en dominios cruzados.
¿Cómo funciona?
Se basa en alinear representaciones visuales con descripciones de clases en lenguaje natural, lo que mejora la generalizabilidad en regímenes de poca data. Incluye tres variantes: FLIP-Vision (FLIP-V), FLIP-Image-Text Similarity (FLIP-IT) y FLIP-Multimodal-Contrastive-Learning (FLIP-MCL):
- FLIP-V es la variante más simple de FLIP y utiliza el modelo base ViT para detectar ataques de presentación facial. En esta variante, el modelo se entrena en un conjunto de datos de entrenamiento que incluye imágenes de personas reales y ataques de presentación facial. El modelo aprende a distinguir entre imágenes genuinas y ataques de presentación facial mediante la comparación de las representaciones de imagen de las imágenes de entrenamiento.
- FLIP-IT es otra variante de FLIP que utiliza la supervisión del lenguaje natural para generar representaciones más generalizables. En esta variante, el modelo se entrena en un conjunto de datos de entrenamiento que incluye imágenes de personas reales y ataques de presentación facial, así como descripciones de texto de las imágenes. El modelo aprende a distinguir entre imágenes genuinas y ataques de presentación facial mediante la comparación de las representaciones de imagen y texto de las imágenes de entrenamiento.
- FLIP-MCL es la variante más avanzada y utiliza una estrategia de aprendizaje contrastivo multimodal para generar representaciones más generalizables. En esta variante, el modelo se entrena en un conjunto de datos de entrenamiento que incluye imágenes de personas reales y ataques de presentación facial, así como descripciones de texto de las imágenes. El modelo aprende a distinguir entre imágenes genuinas y ataques de presentación facial mediante la comparación de las representaciones de imagen y texto de las imágenes de entrenamiento, y utiliza una estrategia de aprendizaje contrastivo multimodal para mejorar la capacidad de generalización del modelo.
Estas variantes utilizan diferentes estrategias, como la alineación de la representación de imágenes con promociones textuales, y el aprendizaje contrastivo multimodal para mejorar la detección de ataques de presentación.
¿En qué se diferencia de los métodos más tradicionales de detección?
A diferencia de los enfoques tradicionales de FAS, que a menudo tienen una generalización limitada a tipos de spoof no vistos, sensores de cámara y condiciones ambientales, FLIP mejora la generalización para la tarea FAS al utilizar pre-entrenamiento multimodal y alineación con lenguaje natural. Esto lo hace más eficaz en situaciones de dominios cruzados y con datos limitados.
Enfoque impulsado por la identidad implícita (IID)
¿En qué consiste el método?
El enfoque IID se centra en la identificación de identidades explícitas e implícitas en las imágenes faciales. En el contexto de face swapping, la identidad explícita se refiere a la apariencia visible del rostro, mientras que la identidad implícita abarca información subyacente crucial para la detección de deepfakes.
¿Cómo funciona?
El marco IID utiliza una combinación de pérdida de contraste de identidad explícita (EIC) y exploración de identidad implícita (IIE) para diferenciar entre muestras reales y falsas en el espacio de características, mejorando la detección de deepfakes y face swapping.
¿En qué se diferencia de los métodos más tradicionales de detección?
A diferencia de otros métodos, que generalmente se centran solo en identidades explícitas (apariencia visible del rostro), IID también considera identidades implícitas, abordando así las limitaciones de los métodos tradicionales en la detección de técnicas de falsificación más sofisticadas. Este enfoque no solo ha demostrado ser efectivo en la detección de face swapping, sino que también ofrece una generalización robusta en varios conjuntos de datos, lo que demuestra su capacidad para adaptarse a diferentes tipos de falsificaciones.
Aprendizaje dinámico de grafos espacio-frecuencia (SFGD)
¿En qué consiste?
El método SFDG aborda las limitaciones de los métodos anteriores en la integración de información de frecuencia con el contenido de la imagen, utilizando el aprendizaje dinámico de grafos para analizar características espaciales y de frecuencia. Podemos indicar que desarrolla un modelo de grafos para explotar las relaciones de los dominios espacial y de frecuencia para detectar pistas sutiles de falsificación.
¿Cómo funciona?
Este método consta de tres módulos principales: la extracción de frecuencia adaptable al contenido o Content-guided Adaptive Frequency Extraction (CAFE), el aprendizaje de mapas de atención multidominio o Multiple Domains Attention Map Learning (MDAML) y la red dinámica de fusión de características espaciales y de frecuencia basada en grafos o Dynamic Graph based Spatial-Frequency Feature Fusion (DG-SF3Net).
El funcionamiento es el siguiente: el módulo CAFE extrae pistas de frecuencia adaptadas al contenido, lo que permite identificar características de frecuencia específicas que son difíciles de falsificar. El módulo MDAML enriquece las características contextuales de frecuencia espacial con mapas de atención multiescala, lo que ayuda a detectar patrones de manipulación más complejos. Finalmente, la red DG-SF3Net explora la relación de alto orden entre las características espaciales y de frecuencia mediante la convolución de grafos y la interacción entre canales y nodos, lo que permite detectar manipulaciones más sutiles y sofisticadas.
¿En qué se diferencia de los métodos más tradicionales de detección?
El método propuesto de grafos dinámicos tiene varias ventajas sobre los métodos existentes de detección de deepfakes. En primer lugar, el enfoque SFDG extrae pistas de frecuencia adaptadas al contenido, lo que permite identificar características de frecuencia específicas que son difíciles de falsificar. En segundo lugar, el método utiliza grafos dinámicos para fusionar integralmente las características espaciales y de frecuencia, lo que permite detectar manipulaciones más sutiles y sofisticadas. Además, utiliza mapas de atención multidominio para enriquecer las características contextuales de frecuencia espacial, lo que ayuda a detectar patrones de manipulación más complejos.
Detección de deepfake sin conocimiento de identidad (ID-unaware deepfake detection model)
¿En qué consiste el método?
El ID-unaware Deepfake Detection Model es una metodología diseñada para reducir la influencia del fenómeno conocido como «Implicit Identity Leakage» en la detección de deepfakes. Este fenómeno se refiere a la tendencia de los clasificadores binarios a aprender representaciones de identidad no esperadas en las imágenes, lo cual puede perjudicar su capacidad de generalización.
¿Cómo funciona?
Este modelo utiliza un módulo de detección de artefactos (Artifact Detection Module, ADM) y un método de intercambio facial a múltiples escalas (Multi-scale Facial Swap, MFS). El ADM detecta áreas de artefactos en imágenes falsas usando anclas a múltiples escalas, lo que ayuda a centrarse en áreas locales de las imágenes y a reducir la atención a la información global de identidad. El MFS, por otro lado, manipula imágenes falsas y originales para generar nuevas imágenes falsas con anotaciones de posición de áreas de artefactos, enriqueciendo así las características de los artefactos en el conjunto de entrenamiento.
¿En qué se diferencia de los métodos más tradicionales de detección?
Este modelo se enfoca en detectar artefactos locales y en reducir la dependencia de la información global de identidad, lo que mejora su generalización y efectividad en la detección de deepfakes.
Instance-Aware Domain Generalization (IADG)
¿En qué consiste?
IADG es un marco para la detección de fraudes de identidad que se centra en la generalización de dominios mediante la alineación de características a nivel de instancia. Busca debilitar la sensibilidad de las características a estilos específicos de instancias para mejorar la generalización en escenarios no vistos.
¿Cómo funciona?
Incluye tres componentes: AIAW, que elimina adaptativamente la correlación de características sensibles al estilo; DKG, que genera filtros adaptativos a las instancias; y CSA, que crea muestras diversificadas en estilos para cada instancia. Estos componentes trabajan conjuntamente para mejorar la capacidad de generalización del modelo.
¿En qué se diferencia de los métodos más tradicionales de detección?
Los enfoques actuales suelen hacer uso de etiquetas de dominio y enfocarse en la alineación a nivel de dominio, por contra IADG opera a nivel de instancia, lo que permite una generalización más efectiva en una variedad de escenarios no vistos.
Categorical Style Assembly (CSA)
¿En qué consiste el método?
CSA un componente del marco IADG que genera muestras con estilos diversificados para simular cambios de estilo a nivel de instancia.
¿Cómo funciona?
Este método considera la diversidad de muestras de diversas fuentes para generar nuevos estilos en un espacio de características más amplio. Además, introduce el concepto categórico en la tarea FAS y aumenta por separado las muestras reales y falsas para prevenir cambios negativos en las etiquetas entre diferentes clases.
¿En qué se diferencia de los métodos más tradicionales de detección?
A diferencia de los enfoques tradicionales que podrían mezclar estilos de fuente sin considerar la frecuencia o la información categórica, CSA genera estilos de manera más diversificada y contextualizada, lo que mejora la capacidad del modelo para manejar variaciones de estilo más amplias y complejas.
Dynamic Kernel Generator (DKG)
¿En qué consiste?
DKG es un componente del marco IADG que se centra en la generación automática de filtros adaptativos a las instancias, lo cual es clave para la generalización del dominio.
¿Cómo funciona?
DKG utiliza un enfoque de filtrado dinámico para adaptarse a la diversidad de las muestras en múltiples dominios fuente. Esto facilita el aprendizaje de características adaptativas a las instancias, lo cual es crucial para la generalización en diferentes contextos y tipos de ataques
¿En qué se diferencia de los métodos más tradicionales de detección?
A diferencia de los métodos tradicionales que utilizan filtros estáticos, DKG se adapta a las características específicas.
Enfoque FAS-wrapper
¿En qué consiste?
El método FAS-wrapper se centra en el aprendizaje multidominio para la actualización de modelos anti-spoofing de rostro (MD-FAS). Proporciona una forma de actualizar un modelo FAS preentrenado para que funcione bien tanto en dominios fuente como en objetivos, utilizando solo datos del dominio objetivo para la actualización
¿Cómo funciona?
Incluye un módulo llamado estimador de región de spoof (SRE) para identificar huellas de spoof en la imagen y un marco llamado FAS-wrapper que transfiere el conocimiento de los modelos preentrenados e integra sin problemas con diferentes modelos FAS. Este enfoque ayuda a combatir el olvido catastrófico durante la actualización y mantiene la capacidad original del modelo FAS
¿En qué se diferencia de los métodos más tradicionales de detección?
A diferencia de los métodos tradicionales, el FAS-wrapper maneja el problema de actualización de modelos en diferentes dominios sin necesidad de reentrenar completamente el modelo FAS desde cero. En los enfoques convencionales, la adaptación a nuevos dominios a menudo implica un extenso reentrenamiento con datos del nuevo dominio, lo cual puede ser costoso en términos de recursos y tiempo. Además, estos métodos tradicionales a menudo sufren de olvido catastrófico, donde la adquisición de conocimientos nuevos provoca la pérdida de conocimientos previamente aprendidos.
Asymmetric Instance Adaptive Whitening (AIAW)
¿En qué consiste el método?
AIAW se enfoca en la generalización de dominio en detección de spoofing facial, adaptando de manera asimétrica la correlación de características sensibles al estilo para cada instancia, y así mejorar la generalización.
¿Cómo funciona?
Este método suprime selectivamente la covarianza sensible y resalta la insensible. Utiliza la normalización de instancia para producir una característica normalizada y luego calcula la matriz de covarianza de esta característica. Se aplican diferentes proporciones selectivas para suprimir la covarianza sensible en caras reales y falsas.
¿En qué se diferencia de los métodos más tradicionales de detección?
Lo que hace diferente a AIAW de otros enfoques es que no se basa en etiquetas de dominio artificial y se enfoca en la generalización de dominio a nivel de instancia. Esto lo hace más efectivo para adaptarse a variaciones específicas de instancia y para mejorar la generalización en escenarios no vistos.
Medidas de autenticación avanzada: biometría y liveness detection
Las medidas de autenticación avanzada, en particular la biometría y la liveness detection, representan un cambio significativo en la forma en que se verifica la identidad en el entorno digital. La biometría, que se basa en características físicas únicas de un individuo, es considerado como uno de los métodos de autenticación más seguros. Este enfoque biométrico ofrece una capa adicional de seguridad, ya que las características biológicas son inherentemente más difíciles de replicar o falsificar en comparación con las tradicionales contraseñas.
Por otro lado, encontramos la prueba de vida o liveness detection, una técnica complementaria a la biometría que analiza la vitalidad de una persona en un proceso digital. Este método busca confirmar que el usuario presente frente al sistema es una persona real y no un ataque.
Para lograr esto, se puede pedir al usuario que realice ciertos movimientos faciales como parpadeo, gestos, cambios en la expresión, movimientos oculares, entre otros (prueba de vida activa). Proveedores de tecnologías como Mobbeel realizan también lo que se conoce como prueba de vida pasiva. A diferencia de la prueba de vida activa, donde el usuario realiza acciones específicas para demostrar su presencia física, la prueba de vida pasiva se lleva a cabo de manera continua y discreta, analizando un micro video del usuario, sin que este tenga que realizar acciones adicionales.

Estos indicadores y análisis son difíciles de replicar para un sistema automatizado por parte de un impostor o mediante el uso de imágenes o videos falsos.
El futuro: innovación tecnológica y adaptabilidad para la prevención del fraude
El futuro de la seguridad digital se desdibuja como un entorno donde la adaptabilidad y la innovación tecnológica serán fundamentales para hacer frente a los desafíos emergentes del fraude de identidad. En el futuro inminente, la integración de tecnologías avanzadas y estrategias proactivas se convertirá en la norma para garantizar protección de la identidad digital.
Una de las tendencias destacadas se centra en el desarrollo de sistemas de autenticación más inteligentes y adaptables. Estos sistemas se alejan de las autenticaciones tradicionales basadas únicamente en contraseñas hacia un enfoque multifactorial que combina múltiples capas de verificación. La fusión de biometría, liveness detection y machine learning permitirá la creación de un ecosistema de seguridad más sólido y dinámico.
La inteligencia artificial (IA) y el machine learning jugarán un papel crucial en la detección y prevención del fraude de identidad. Los algoritmos de IA son cada vez más sofisticados, capaces de analizar grandes volúmenes de datos para identificar patrones y anomalías que puedan indicar posibles intentos de fraude. La tendencia parece apuntar hacia la adaptación del dominio y hacia la capacidad de generalización. Para lograr esta adaptabilidad, las investigaciones comentadas se han enfocado en desarrollar técnicas que permitan a los modelos aprender de manera continua y dinámica, actualizando constantemente su comprensión de lo que constituye un comportamiento normal y anormal. El reto radica en cómo enseñar a la IA a reconocer patrones sutiles o variaciones que podrían indicar una nueva forma de ataque, incluso en situaciones donde no hay datos históricos disponibles.
Además, se espera una mayor convergencia entre las tecnologías biométricas y la Internet de las cosas (IoT), permitiendo una autenticación más ubicua y contextual. Dispositivos cotidianos, desde teléfonos inteligentes hasta dispositivos domésticos conectados, podrían integrar sistemas de autenticación biométrica para garantizar una identificación más segura y transparente en diferentes escenarios y entornos.
La privacidad y la seguridad de los datos serán un foco primordial en esta evolución. La implementación de estándares más estrictos de protección de datos y la adopción de prácticas de privacidad por diseño serán esenciales para garantizar que la recopilación y el uso de información biométrica se realicen de manera ética y conforme a regulaciones de privacidad.
Escríbenos si quieres incorporar un sistema de verificación de identidad capaz de detectar fraudes de identidad con tecnología avanzada.

Soy una mente inquieta con conocimientos en derecho, marketing y empresas. Una alquimista de la palabra, enamorada del neuromarketing y del copywriting, que ayuda a Mobbeel a seguir creciendo.

GUÍA
Identifica a tus usuarios mediante su cara
En esta dualidad analógico-digital, uno de los procesos que sigue siendo crucial para garantizar la seguridad es la verificación de identidad a través del reconocimiento facial. La cara, siendo el espejo del alma, proporciona una defensa única contra el fraude, aportando fiabilidad al proceso de identificación.


