
“Toda tecnología lo suficientemente avanzada es indistinguible de la magia”.
Este conocido aforismo de Arthur C. Clarke sigue siendo un marco perfecto para entender la percepción de las tecnologías de verificación biométrica.
Durante décadas, series y películas nos han mostrado sistemas que identifican a personas de forma instantánea, generando un aura de fascinación alrededor de estas soluciones. Sin embargo, lo que antes parecía pura ciencia ficción, hoy forma parte de nuestra vida cotidiana: desbloqueamos móviles con la huella, confirmamos transacciones con nuestra voz y abrimos cuentas bancarias con una selfie.
La pregunta ya no es «¿es esto posible?», sino «¿cómo funciona exactamente esta tecnología?»
¿Cómo funcionan las tecnologías de identificación biométrica?
La biometría utiliza rasgos físicos o del comportamiento que nos hacen únicos como individuos. Algunos ejemplos comunes incluyen la huella dactilar, el rostro, el iris o incluso características más dinámicas como el tono de voz, el ritmo de tecleo o la firma. No todas las características son igualmente fáciles de capturar y procesar ni aportan la misma fiabilidad o accesibilidad, por lo que su elección dependerá de los requisitos de cada sistema final.
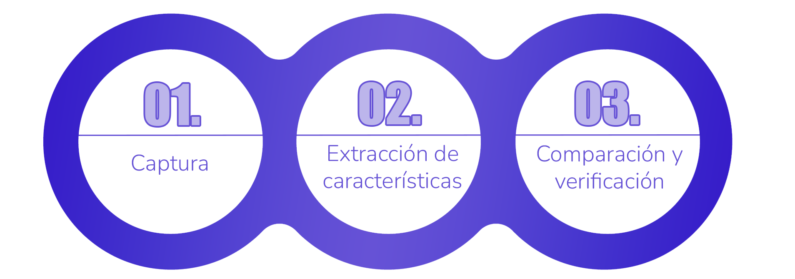
De forma general, un proceso con biometría se puede dividir en tres fases clave:
- Captura: Se utilizan dispositivos como cámaras, micrófonos o sensores para registrar el rasgo biométrico.
- Extracción de características: A partir del dato bruto, un sistema entrenado es capaz de crear vectores de características (huellas biométricas) que modelan el rasgo original.
- Comparación y verificación: El sistema compara la representación matemática capturada con una base de datos almacenada para confirmar o rechazar la identidad.
Evolución tecnológica
Antes de la llegada del aprendizaje profundo, el éxito de los sistemas biométricos dependía en gran medida de la selección manual de características relevantes. Por ejemplo, en un sistema de voz, era necesario definir de antemano qué características se utilizarían para modelar ese rasgo: la frecuencia fundamental, desviaciones, formantes…
Hoy, gracias a los avances en hardware y al acceso a grandes bases de datos, las redes neuronales profundas han revolucionado este paradigma. Estos sistemas son capaces de aprender automáticamente las características más representativas para cada caso, analizando patrones con diferentes niveles de abstracción:
- Capas iniciales: Identifican detalles básicos como bordes, sombras o rasgos frecuenciales.
- Capas intermedias: Reconocen formas, texturas o timbres.
- Capas profundas: Detectan estructuras completas como rasgos faciales o tono de voz.
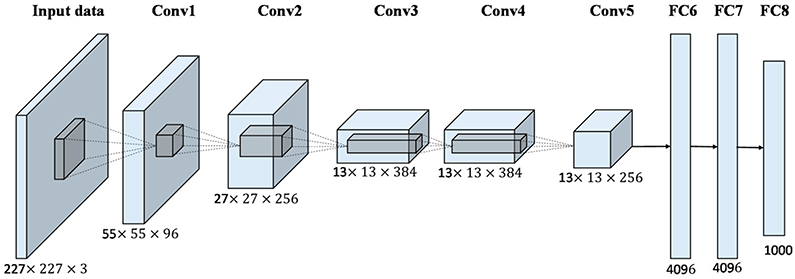

Este enfoque permite un entrenamiento extremo a extremo, mejorando el
desempeño de los extractores de características al hacerlos más robustos.
![]() Una vez que cualquiera de los rasgos biométricos anteriormente descritos ha sido capturado con un dispositivo electrónico (una cámara, un micrófono, un sensor de huellas…) es posible extraer una serie de características que representen de la mejor manera posible a cada uno de ellos.
Una vez que cualquiera de los rasgos biométricos anteriormente descritos ha sido capturado con un dispositivo electrónico (una cámara, un micrófono, un sensor de huellas…) es posible extraer una serie de características que representen de la mejor manera posible a cada uno de ellos.
Cómo proteger los datos biométricos
El uso masivo de la biometría plantea preguntas críticas sobre la privacidad y la protección de datos. A diferencia de contraseñas o PINs, los datos biométricos son inmutables; no podemos cambiar nuestras huellas dactilares o rostro en caso de que sean comprometidos. Esto los convierte en un objetivo atractivo para los ciberdelincuentes.
Para mitigar estos riesgos, los fabricantes de biometría trabajamos activamente en soluciones que permitan aportar el máximo grado de seguridad en la operativa:
- Seguridad física y lógica en el almacenamiento de datos biométricos: El almacenamiento de datos biométricos requiere una combinación de medidas físicas y lógicas para prevenir accesos no autorizados. Desde el punto de vista físico, estas bases de datos deben almacenarse en centros que con certificaciones de seguridad como ISO 27001.
- Cifrado avanzado para la protección de datos: Los datos biométricos, al ser únicos e irremplazables, requieren cifrados robustos para evitar ingeniería inversa. Técnicas como el cifrado homomórfico permiten realizar cálculos directamente sobre datos cifrados, eliminando la necesidad de desencriptarlos y minimizando el riesgo de exposición. Alternativamente, la criptobiometría integra características biométricas con criptografía para asegurar que las plantillas no puedan reconstruirse ni utilizarse fuera del sistema original.
- Pruebas de conocimiento cero: Este tipo de técnicas permiten verificar la autenticidad de una identidad sin ser revelada por completo. Se trata de una aproximación muy interesante y en línea con las regulaciones que -intentan dar respuesta a la preocupación por la privacidad de los datos personales.
Marco legal y ética en la biometría
La implementación de sistemas biométricos está sujeta a normativas estrictas, como el Reglamento General de Protección de Datos (RGPD) y la nueva Ley de Inteligencia Artificial (IA Act) en Europa. Estas normativas no solo regulan el consentimiento, el almacenamiento y el uso de datos biométricos, sino también los riesgos asociados con el uso de tecnologías basadas en inteligencia artificial, incluidas las aplicaciones biométricas. Aseguran que las empresas que gestionan datos biométricos adopten medidas adecuadas para proteger la privacidad y evitar posibles abusos, al tiempo que garantizan que los sistemas de IA sean justos, transparentes y explicables. En concreto, deben cumplirse los principios de proporcionalidad en el uso y el propósito, la transparencia en el uso de estos sistemas y el consentimiento explícito por parte de los usuarios.
Además de los aspectos regulatorios, es esencial abordar los sesgos en los algoritmos biométricos, una preocupación creciente en el desarrollo de tecnologías basadas en inteligencia artificial. Los estudios, como los realizados por el NIST (National Institute of Standards and Technology), han evidenciado que los sistemas de reconocimiento facial, por ejemplo, pueden presentar tasas de error más altas para personas de determinadas etnias, géneros o características físicas que no están suficientemente representadas en los datos de entrenamiento.

El informe de NIST sobre sesgos demográficos en tecnologías de biometría y reconocimiento facial, que analiza diversas bases de datos y algoritmos, mostró que los sistemas pueden ser propensos a errores significativos cuando no se entrenan con una diversidad adecuada de datos. En este sentido, es crucial entrenar modelos con bases de datos lo más diversas y representativas posible, que reflejen la heterogeneidad de la población global, a fin de reducir el riesgo de sesgos y mejorar la equidad y la precisión del sistema.
En Mobbeel, somos conscientes de que la biometría es tan potente como una varita mágica. Por eso, seguimos explorando nuevas posibilidades con el objetivo de ofrecer soluciones que no solo estén a la vanguardia de la innovación, sino que también garanticen la máxima seguridad y respeto por la privacidad de nuestros usuarios.
¡Que la magia continúe!

Soy el responsable del departamento de I+D de Mobbeel y trabajo junto con el resto del equipo en la investigación y desarrollo de tecnologías de biométricas y de verificación de identidad para la mejora continua de nuestros productos.

GUÍA
Identifica a tus usuarios mediante su cara
En esta dualidad analógico-digital, uno de los procesos que sigue siendo crucial para garantizar la seguridad es la verificación de identidad a través del reconocimiento facial. La cara, siendo el espejo del alma, proporciona una defensa única contra el fraude, aportando fiabilidad al proceso de identificación.


